Adding Nodes
This topic describes how to add nodes to kURL clusters. For information about managing nodes on kURL clusters, including removing, rebooting, and resetting nodes, see Managing Nodes.
About Adding Nodes
At the end of the install process, the install script will print out commands for adding nodes, i.e.:
To add worker nodes to this installation, run the following script on your other nodes:
curl -fsSL https://kurl.sh/version/v2023.01.13-1/95569f3/join.sh | sudo bash -s kubernetes-master-address=10.154.15.203:6443 kubeadm-token=pjxtic.8jrj88214t1tcyfq kubeadm-token-ca-hash=sha256:7f3374d6e8f1971d33c6a9edb16bac5bc6e2c98d2f7f6fa4209a8178b749d462 kubernetes-version=1.19.16 docker-registry-ip=10.96.2.26 primary-host=10.154.15.203
Be aware that those commands to add new secondary nodes last 24 hours, and commands to add additional primary nodes in HA mode last for 2 hours. Therefore,
to get new commands, run tasks.sh join_token with the relevant parameters (airgap and ha) on a primary node such as the following examples.
- For single-primary online installation: run
curl -sSL https://kurl.sh/latest/tasks.sh | sudo bash -s join_token - For airgapped HA installation: run
cat ./tasks.sh | sudo bash -s join_token ha airgap
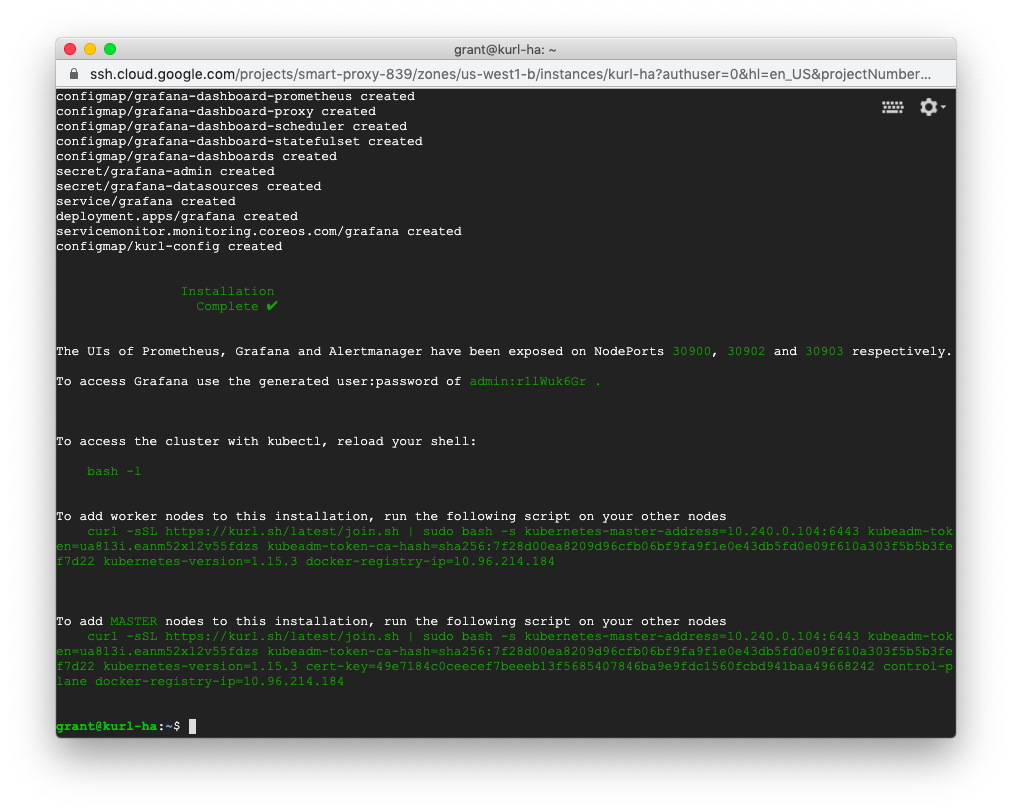
Standard Installations
The install script will print the command that can be run on secondary nodes to join them to your new cluster.
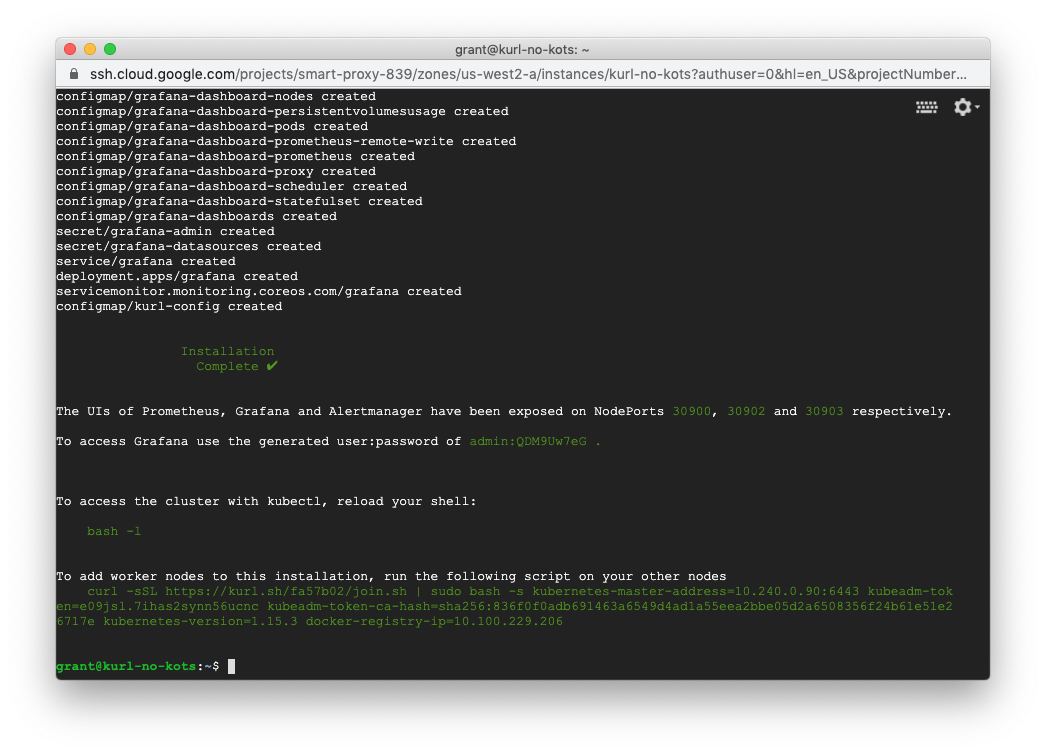
HA Installations
For HA clusters, the install script will print out separate commands for joining secondaries and joining additional primary nodes. See Highly Available K8s for HA install details.